



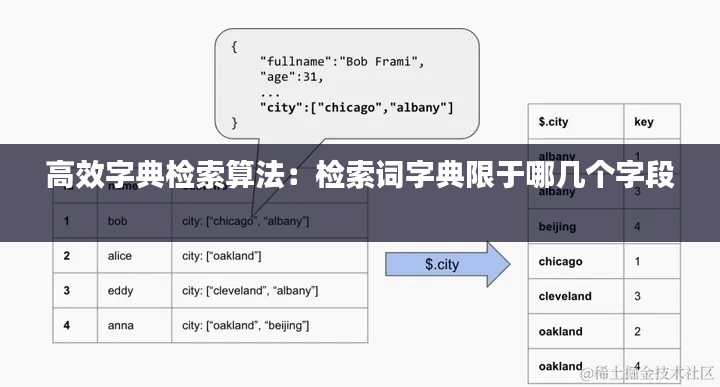
引言
在计算机科学中,字典检索算法是一种非常基础且重要的数据结构。随着大数据时代的到来,高效的数据检索变得尤为重要。字典检索算法的核心目标是实现快速、准确的查找,以满足各种应用场景的需求。本文将探讨几种高效字典检索算法,并分析它们的优缺点。
哈希表(Hash Table)
哈希表是一种基于哈希函数的数据结构,它可以实现快速的元素插入、删除和查找。哈希表通过将关键字映射到一个固定大小的数组(称为哈希桶)中的位置来实现检索。以下是哈希表检索算法的基本步骤:
- 计算关键字哈希值。
- 根据哈希值确定哈希桶的位置。
- 在哈希桶中查找关键字对应的值。
哈希表的优点是检索速度快,时间复杂度为O(1)。然而,哈希表的性能受到哈希函数和哈希桶大小的影响。如果哈希函数设计不当或哈希桶大小不足,可能会导致冲突和性能下降。
二分查找(Binary Search)
二分查找算法适用于有序字典。它通过比较中间元素与目标值,逐步缩小查找范围,直到找到目标值或确定目标值不存在。以下是二分查找算法的基本步骤:
- 确定字典的起始和结束索引。
- 计算中间索引。
- 比较中间索引处的元素与目标值。
- 如果相等,则返回索引;如果不相等,则根据比较结果调整起始或结束索引,并重复步骤2和3。
二分查找算法的时间复杂度为O(log n),其中n是字典中元素的数量。它的优点是查找速度快,但缺点是字典需要事先排序,且不适合动态变化的字典。
平衡二叉搜索树(Balanced Binary Search Tree)
平衡二叉搜索树是一种自平衡的二叉树,如AVL树和红黑树。它通过在插入和删除操作时保持树的平衡,确保查找、插入和删除操作的时间复杂度均为O(log n)。以下是平衡二叉搜索树的基本操作步骤:
- 查找:从根节点开始,比较当前节点与目标值,然后根据比较结果向左或向右移动,直到找到目标值或确定目标值不存在。
- 插入:在树中找到合适的位置插入新节点,并根据需要调整树的结构以保持平衡。
- 删除:删除指定节点,并根据需要调整树的结构以保持平衡。
平衡二叉搜索树的优点是查找、插入和删除操作都具有较好的性能,且不需要预先排序。然而,平衡二叉搜索树的实现相对复杂,需要考虑多种平衡操作。
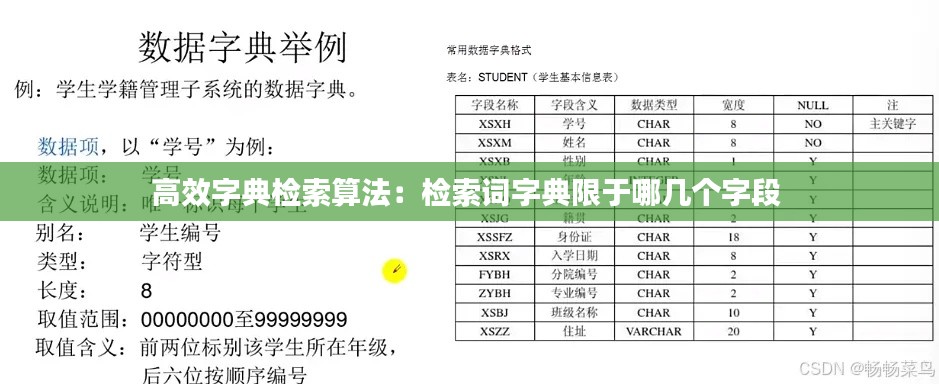
散列表(Trie)
散列表是一种用于字符串检索的特殊数据结构。它通过将字符串的前缀映射到树形结构中的节点来实现快速检索。以下是散列表检索算法的基本步骤:
- 从根节点开始,逐个字符地比较字符串。
- 如果当前字符在节点中存在,则移动到对应的子节点。
- 如果当前字符在节点中不存在,则创建一个新的子节点。
- 当到达字符串的末尾时,检查节点是否标记为结束符。
散列表的查找时间复杂度为O(m),其中m是字符串的长度。它的优点是查找速度快,尤其适用于前缀匹配的检索场景。然而,散列表的空间复杂度较高,且不适用于非前缀匹配的检索。
结论
本文介绍了几种高效字典检索算法,包括哈希表、二分查找、平衡二叉搜索树和散列表。每种算法都有其优缺点,适用于不同的应用场景。在实际应用中,应根据具体需求选择合适的算法,以实现高效的数据检索。
转载请注明来自福建光数数字技术有限公司,本文标题:《高效字典检索算法:检索词字典限于哪几个字段 》






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...