



引言
在数据分析领域,CSV(逗号分隔值)文件是一种非常常见的数据存储格式。由于其简单性和灵活性,CSV文件被广泛应用于数据交换和存储。然而,随着数据量的不断增长,读取CSV文件的速度成为了一个关键问题。本文将探讨如何高效地读取CSV文件,以提高数据处理效率。
选择合适的工具
在读取CSV文件时,选择合适的工具至关重要。以下是一些流行的工具,它们都提供了高效读取CSV文件的功能:
- Pandas:Python中一个强大的数据分析库,提供了丰富的数据结构和数据分析工具,可以轻松读取和操作CSV文件。
- NumPy:Python中一个基础的科学计算库,虽然本身不直接支持读取CSV文件,但可以与Pandas结合使用。
- Python的内置csv模块:适用于简单的CSV文件读取任务。
- Java的OpenCSV:适用于Java编程语言,提供了高效的CSV文件读取功能。
- Excel:虽然主要用于数据可视化,但也可以快速打开和读取CSV文件。
使用合适的数据类型
在读取CSV文件时,指定正确的数据类型可以显著提高效率。以下是一些常见的CSV文件数据类型及其在Pandas中的对应类型:
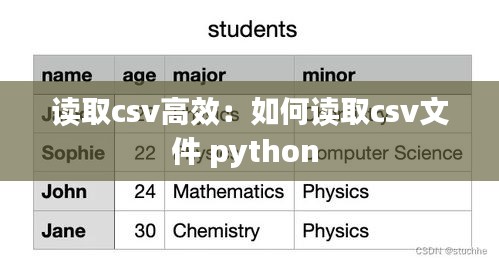
- 整数:`int`
- 浮点数:`float`
- 字符串:`str`
- 布尔值:`bool`
如果CSV文件中的数据类型不明确,可以使用Pandas的`infer_objects()`方法自动推断数据类型,但这种方法可能会降低读取速度。
使用适当的方法读取数据
不同的工具和库提供了不同的方法来读取CSV文件。以下是一些提高读取效率的方法:
- 使用迭代器:对于非常大的CSV文件,使用迭代器可以逐行读取数据,而不是一次性将整个文件加载到内存中。
- 使用块读取:一些库允许按块读取数据,这可以减少内存使用并提高速度。
- 跳过不需要的列:如果CSV文件包含一些不需要的列,可以只读取需要的列,以减少处理时间。
- 使用缓冲区:一些库允许调整缓冲区大小,以优化内存使用和读取速度。
并行处理
对于非常大的CSV文件,可以考虑使用并行处理来提高读取效率。以下是一些实现并行处理的方法:
- 多线程:在Python中,可以使用`concurrent.futures`模块来创建多线程任务,并行读取CSV文件的不同部分。
- 多进程:在Python中,可以使用`multiprocessing`模块来创建多进程任务,利用多核CPU的优势来并行处理数据。
- 分布式处理:对于非常大的数据集,可以使用分布式计算框架,如Apache Spark,来在多台机器上并行处理数据。
优化读取性能的技巧
以下是一些优化CSV文件读取性能的通用技巧:
- 使用压缩文件:如果CSV文件很大,可以考虑将其压缩,以减少读取时间。
- 避免使用索引:如果不需要对CSV文件进行随机访问,可以关闭索引,以减少读取时间。
- 优化数据格式:对于复杂的CSV文件,考虑优化数据格式,例如使用更紧凑的数据类型或减少数据冗余。
结论
高效地读取CSV文件对于数据分析和处理至关重要。通过选择合适的工具、使用合适的数据类型、采用适当的方法、并行处理以及优化读取性能,可以显著提高CSV文件读取的效率。这些技巧可以帮助您更快地处理数据,从而更好地利用数据分析和处理的优势。
转载请注明来自福建光数数字技术有限公司,本文标题:《读取csv高效:如何读取csv文件 python 》
百度分享代码,如果开启HTTPS请参考李洋个人博客






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...