



引言
在计算机科学中,目录遍历是一个常见且重要的任务,它涉及到访问和操作文件系统中的目录和文件。无论是文件搜索、文件同步还是文件管理工具,目录遍历都是基础功能之一。然而,随着文件系统的复杂性和文件数量的增加,高效的目录遍历变得尤为重要。本文将探讨高效目录遍历的方法、技术和最佳实践。
目录遍历的基本概念
目录遍历通常指的是遍历文件系统中的目录结构,访问其中的文件和子目录。这可以通过递归或迭代的方式来实现。递归方法通常使用递归函数来遍历每个子目录,而迭代方法则可能使用栈或队列来管理待遍历的目录。
递归目录遍历
递归目录遍历是一种自顶向下的遍历方法,它通过调用自身来遍历子目录。这种方法简单直观,但在处理大量文件或深层目录结构时可能会遇到性能问题。
以下是一个简单的递归目录遍历的伪代码示例:
def recursive_directory_traversal(directory):
for entry in os.listdir(directory):
path = os.path.join(directory, entry)
if os.path.isdir(path):
recursive_directory_traversal(path)
else:
process_file(path)迭代目录遍历
迭代目录遍历通常使用栈或队列来管理待遍历的目录。这种方法可以避免递归带来的栈溢出风险,并且在处理大量文件时通常更高效。
以下是一个使用栈的迭代目录遍历的伪代码示例:
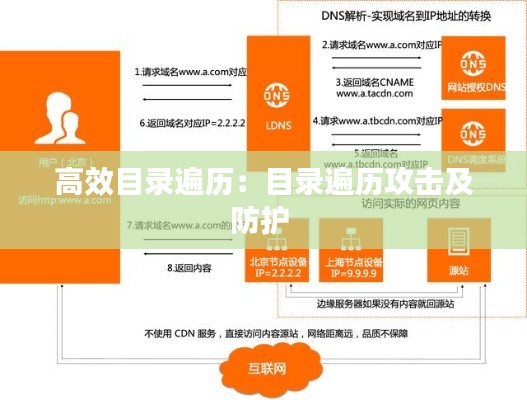
def iterative_directory_traversal(directory):
stack = [directory]
while stack:
current_directory = stack.pop()
for entry in os.listdir(current_directory):
path = os.path.join(current_directory, entry)
if os.path.isdir(path):
stack.append(path)
else:
process_file(path)性能优化
在实现目录遍历时,性能优化是关键。以下是一些提高目录遍历效率的策略:
使用多线程或多进程:在遍历目录时,可以使用多线程或多进程来并行处理文件,从而提高效率。
避免重复操作:在遍历过程中,避免重复读取同一文件或目录,可以通过缓存或哈希表来减少不必要的操作。
使用异步I/O:在遍历文件时,使用异步I/O操作可以减少等待时间,提高整体效率。
优化文件系统:确保文件系统本身具有良好的性能,例如使用SSD而非HDD,可以显著提高文件访问速度。
最佳实践
以下是实现高效目录遍历的一些最佳实践:
明确遍历目标:在开始遍历之前,明确遍历的目的和需求,这有助于选择合适的遍历方法和优化策略。
测试和评估:在实现遍历逻辑后,对不同的文件系统和目录结构进行测试和评估,以确保性能满足要求。

代码可维护性:编写清晰、可维护的代码,便于后续的优化和扩展。
错误处理:合理处理遍历过程中可能出现的错误,如文件访问权限不足、文件损坏等。
结论
高效目录遍历是文件系统操作中的一个重要环节,它直接影响到应用程序的性能和用户体验。通过理解目录遍历的基本概念、选择合适的遍历方法、实施性能优化和遵循最佳实践,可以有效地提高目录遍历的效率。在设计和实现目录遍历功能时,这些因素都应被充分考虑。
转载请注明来自福建光数数字技术有限公司,本文标题:《高效目录遍历:目录遍历攻击及防护 》






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...